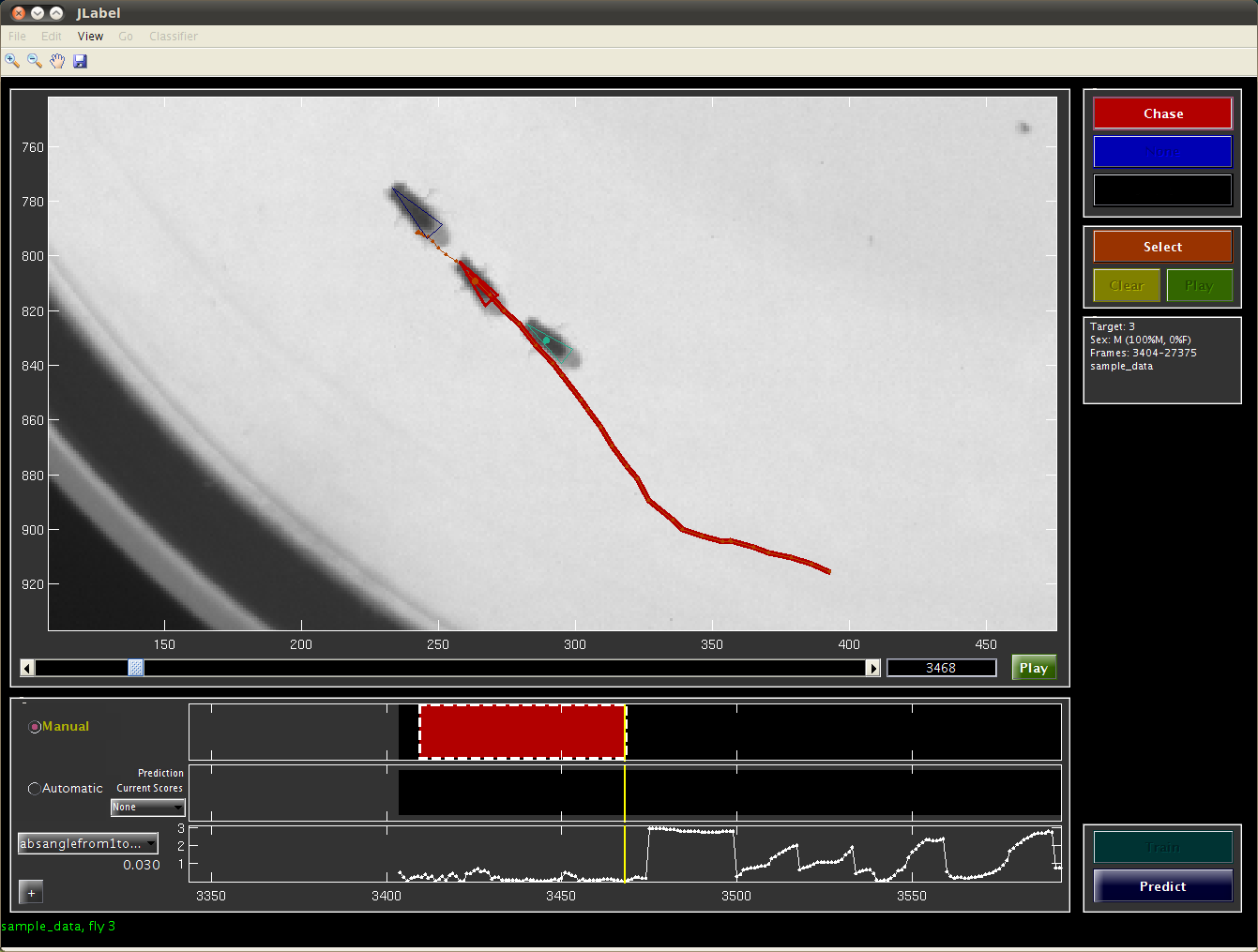
JAABA interface screencap while labeling a bout of chase
JAABA creates classifiers that predict whether or not the animal(s) are performing a given behavior (specified in the Project Configuration) in each frame. In the screen capture below, we are labeling whether the flies are Chasing or not. Thus, the label for each animal in each frame can have one of three values, and there are three buttons on the top-right side of the JAABA interface corresponding to these.
To add or change labels, click the relevant button to put the labeling pen down, then navigate forward or backward in time. The frames being labeled will be outlined in a dashed white box. Click the relevant button again to pick the labeling pen up. All the frames between the pen-down and pen-up frames will be labeled.
Once you have labeled a few bouts of both the behavior and none (i.e., not the behavior), you can train a classifier by pushing the Train button.
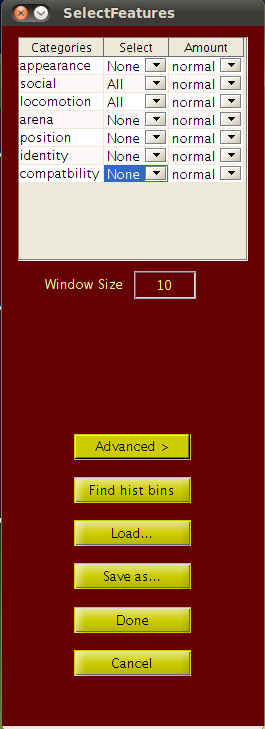
The status bar of the main JAABA interface will indicate that training is occurring. This should take 15-60 seconds, depending on the complexity of the project.The first time you train a classifier, JAABA will show the Select Features interface and ask you to choose the per-frame and window features JAABA will use. To start quickly, select or deselect categories of per-frame by selecting All or None from the Select table column and normal from the Amount column. Also set Window Size to a positive integer. Then, push the Done button to continue.
More details on perframe features, window computations and window size can be found here.
In JAABA, you can use the output of previously trained behavior classifiers as inputs for the current behavior classifier. To do this, select the menu Classifier->Change Score Features. Use the Add and Remove buttons to specify the list of JAABA projects whose output you want to use as inputs. Note that the scores/predictions for the classifiers should already be computed for all the experiments that you want to use for this project.

Initial |
Final |
The middle timeline on the JAABA interface shows the current classifier's predictions. Some frames will have predictions computed, and some will not. You can compute predictions for frames in the following ways:
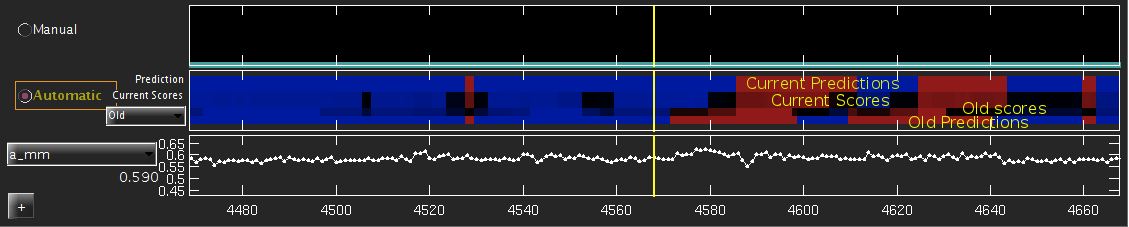
The classifier's predictions are shown in the Automatic Predictions timeline, which is subdivided into the following four parts:
As you review the predictions, you should label frames whose class is incorrectly predicted and for which you are confident of the true class. It's likely that the classifier's predictions are wrong on these frames because there were few similar frames in the training set. Adding such frames to the training set will improve the classifier's prediction on similar frames.
Once you add new labels, you can retrain the classifier by clicking Train again. After retraining, the scores from the previous classifier can be shown at the bottom of the automatic predictions timeline (old in the drop down menu).
Machine learning algorithms are sensitive to inconsistently labeled data. If two similar frames are given the same label, the learning algorithm will spend most of its effort (complexity) in separating these similar looking frames. To train an accurate classifier, you should not label frames for which you are unsure of the correct behavior class. A second advantage of this strategy is that labeling is faster and easier, as it takes longer to decide on labels for difficult examples.
Machine learning algorithms also find it difficult to train an accurate classifier if the number of examples from both classes are unbalanced. To create a more balanced training set, once you train an initial classifier, you should try to label only examples that are incorrectly predicted or have low confidence, and train often. This strategy prevents bloating the training set with obvious examples that make up most of the None behavior class.
Prediction and the scores produced by classifiers are not always smooth and sometimes can result in bouts that are shorter than normal behavioral bouts. This is a limitation of the type of learning algorithm used by JAABA. JAABA finds a classifier which minimizes the total number of frames classified incorrectly, and all frames are given the same weight. With this error criterion, the penalty for an incorrect classification which results in a spurious one-frame-long bout of the behavior is the same as the penalty for missing the start of a behavior bout by one frame.
To address this issue, the user can use post-processing tools to smooth and filter the predictions. The post-processing tool can be accessed by selecting the menu iterm Classifier ->Post-Processing.
hthresh > 0. It then goes through all the bouts of None (not-behavior)
and discards all the bouts that don't have any frames with scores
less than a stricter threshold lthresh < 0. The parameters hthresh and
hthresh are set by the user.In addition, to the above smoothing methods, the user can also set the minimum bout length so as to ignore bouts that have length smaller than the minimum bout length.
Under the Classifier->Classifier parameters menu you can set: